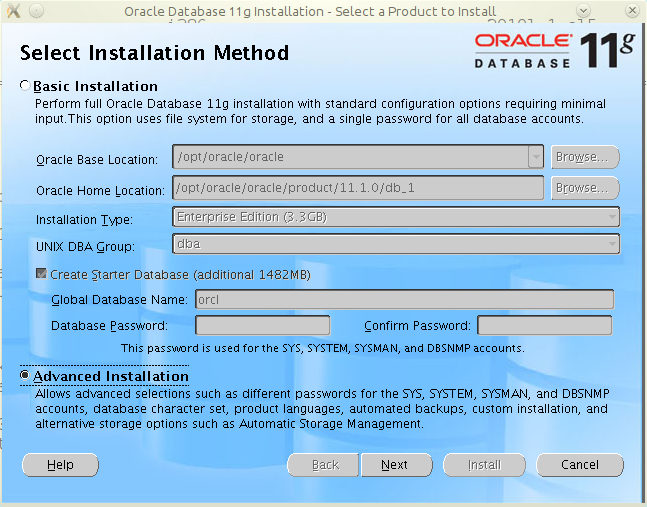
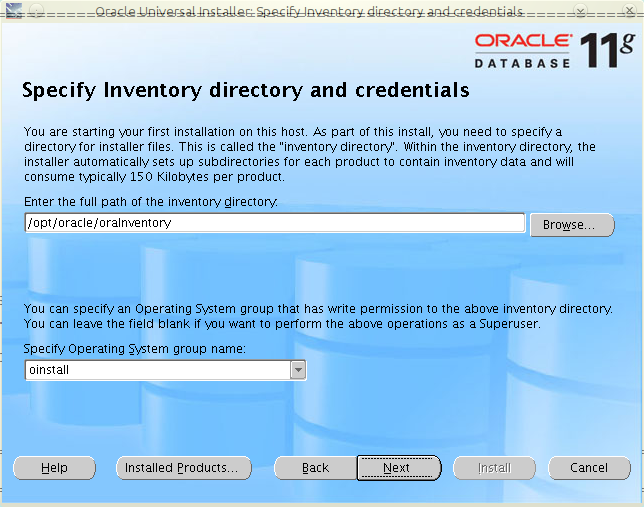
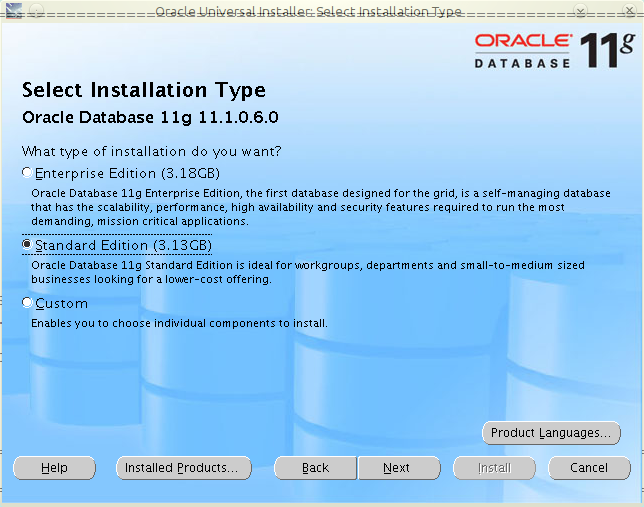
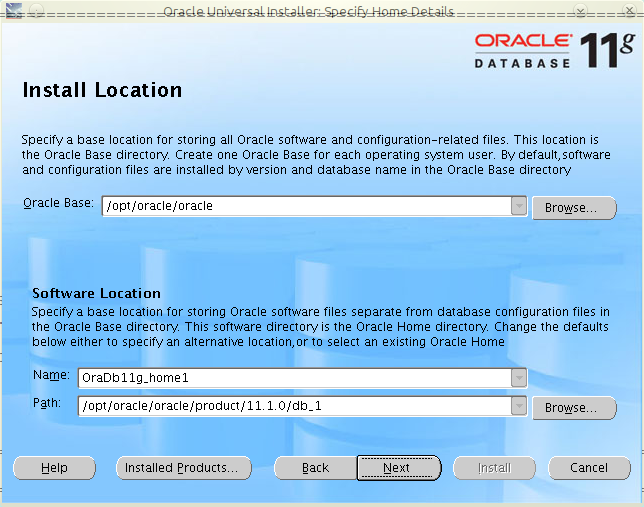
Ostatnimi czasy musiałem przygotować test wydajności dla aplikacji stworzonej przy użyciu szkieletu JBoss Seam. I okazało się, że nie do końca jest to takie trywialne. Poniżej opis, jak przygotować plan testu dla takiej aplikacji (oczywiście, spokojnie można go także użyć do budowy testu dla dowolnej aplikacji webowej).
Wpis składa się z dwóch części:
- JMeter – budowa planu testu aplikacji stworzonej przy użyciu JBoss Seam, część 1
- JMeter – budowa planu testu aplikacji stworzonej przy użyciu JBoss Seam, część 2
Oprogramowanie
W trakcie konstruowania testu używałem następujących aplikacji:
- JMeter 2.3.4
- JBoss EAP 5.1
- JBoss DVD Store – aplikacja przykładowa dostarczana z biblioteką JBoss Seam 2.2.1
Przed przystąpieniem do budowy testu należy aplikację DVD Store zainstalować w serwerze aplikacyjnym.
Jeżeli będziemy się łączyli bezpośrednio z serwerem aplikacyjnym (np. używają linku http://localhost:8080/seam-dvdstore, to warto jeszcze dodać do niego możliwość logowania przychodzących połączeń HTTP. Może to się przydać, aby sprawdzić czy wszystko, czy nie występują jakieś błędy. Można to zrobić modyfikując plik $JBOSS_HOME//server/default/deploy/jbossweb.sar/server.xml. Należy w nim odkomentować nastepujący linie (więcej informacji na ten temat można znaleźć we wpisie Logowanie przychodzących połączeń HTTP w serwerze JBoss AS i Apache Tomcat):
80 81 82 83 | <valve className="org.apache.catalina.valves.AccessLogValve" prefix="localhost_access_log." suffix=".log" pattern="common" directory="${jboss.server.log.dir}" resolveHosts="false" /> |
Plik z logiem będzie znajdował się w katalogu z logami: $JBOSS_HOME//server/default/log/localhost_access_log.DATA.log.
Zebranie danych do testowania
Pierwszym krokiem będzie zebranie stron, na których będzie wywoływany test. Można to zrobić na dwa sposoby:
- zdefiniować wywołanie każdej strony ręcznie
- użyć modułu proxy, który umożliwi nagranie sesji przy użyciu przeglądarki
Ponieważ drugi sposób będzie szybszy, to za jego pomocą nagramy sesję przeglądarki. JMeter udostępnia odpowiedni komponent, który działa jak serwer proxy i pozwala przechwycić żądania z przeglądarki. Konfiguracja jest prosta:
- w JMeter należy dodać następujące komponenty:
- do
Test PlankomponentThread Groupp– pozwala on na konfigurację przebiegu testu: ilość użytkowników, uruchomionych wątków, co ma się dziać w momencie wystąpienia błędu - do
Thread Groupdodać kontrolerRecording Controller– zostaną w nim zapisane wszystkie przechwycone żądanie z komponentu proxy - do
WorkBenchdodać komponentHTTP Proxy Server– to jest nasz serwer proxy, pozwala on na konfiguracja kilku zachowań, teraz najważniejsz będzie port na którym zostanie on uruchomiony. W domyślnej konfiguracji jest to port8080, które jest zajęty przez proces JBossa, należy więc zmienić go na jakiś inny, np.9000.
Wybór portu dla HTTP Proxy Server
- do
- skonfigurować odpowiednio przeglądarkę internetową, tak aby korzystała z serwera proxy. W przypadku Firefoksa powinno wyglądać to mniej więcej tak:

Konfiguracja serwera proxy w Firefoksie
Należy zwrócić uwagę na pole
No Proxy for, domyślnie znajduje się tam wartośćlocalhost, co może uniemożliwić nagranie sesji, jeżeli serwer JBoss jest uruchamiany na maszynie lokalnej.
Teraz czas na pobranie kilku stron, które będą używane następnie w trakcie testu. Należy jeszcze włączyć serwer proxy: w komponencie HTTP Proxy Server należy wybrać przycisk Start. W przypadku aplikacji DVD Store można wykonać takie kroki:
- połączyć się ze stroną http://localhost:8080/seam-dvdstore/home
- można zalogować się na konto wybranego użytkownika, w tym przypadku będzie to użytkownik
user1 - następnie obejrzeć jedną, dwie płyty
- dodać płytę do koszyka i złożyć zamówienia
- wylogować się
Te kroki powinny spowodować, że w aplikacji JMeter pojawi się pod komponentem Record Controler szereg zapytań o strony. Można zauważyć, że znajdują się tam wszystkie wywołania HTTP które wygenerowała przeglądarka, czyli łącznie z pobraniem obrazków, arkuszy stylów czy skryptów JavaScript. W moim przypadku skasowałem te wpisy. W przypadku gdy chcemy pobierać dodatkowe elementy strony, można w ramach zapytania o stronę w JMeter zaznaczyć opcję Retrive All Embedded Resources from HTML files.
W moim przypadku nagrana sesja wygląda następująco:

Nagrana sesja zapytań HTTP
Uporządkowanie testu
Nagrane zapytania do serwera można teraz uporządkować wg funkcji które wykonują oraz trzeba jeszcze dodać kilka dodatkowych komponentów do projektu.
HTTP Cookie Manager– pozwala on na zarządzanie ciasteczkami, które są ustawiane przez badaną stronęGraph Results– tworzy wykres w trakcie uruchamianie testu, można także dodać jakieś inne elementy, które będą zbierały dane z testuSimple Controller– dodanie kilku (w tym przypadku 4) kontrolerów, które pozwolą na pogrupowanie zapytań do serwera- usunąć komponent
Record Component
Grupowanie nie ma wpływu na sam test, ale na pewno zwiększy przejrzystość poszczególnych elementów testu.
Po uporządkowaniu zapytań, wygląda to następująco:

JMeter - grupowanie zapytań