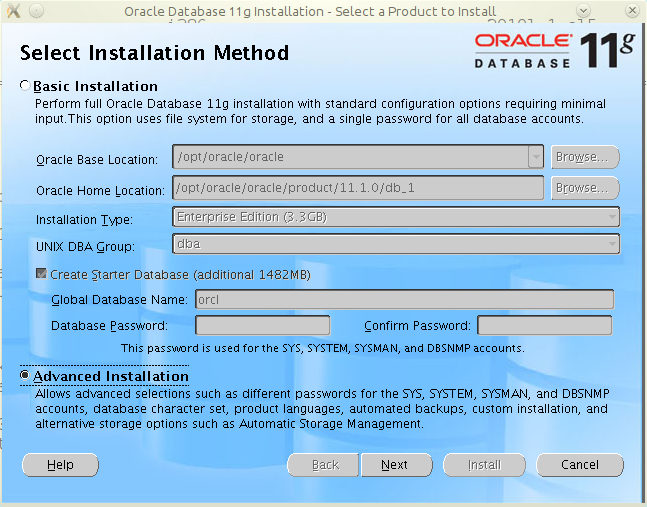
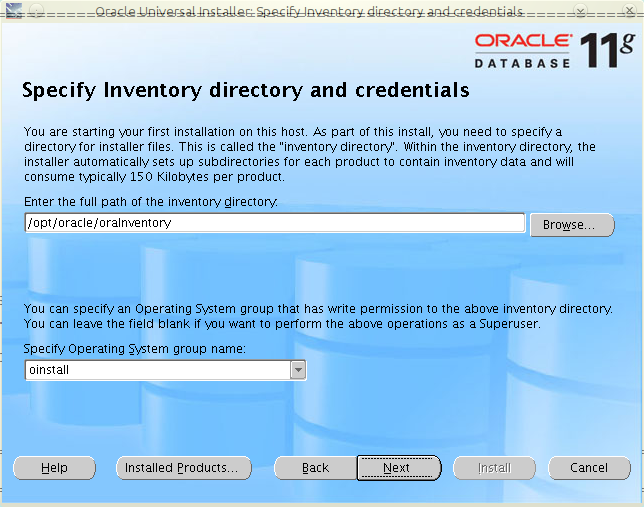
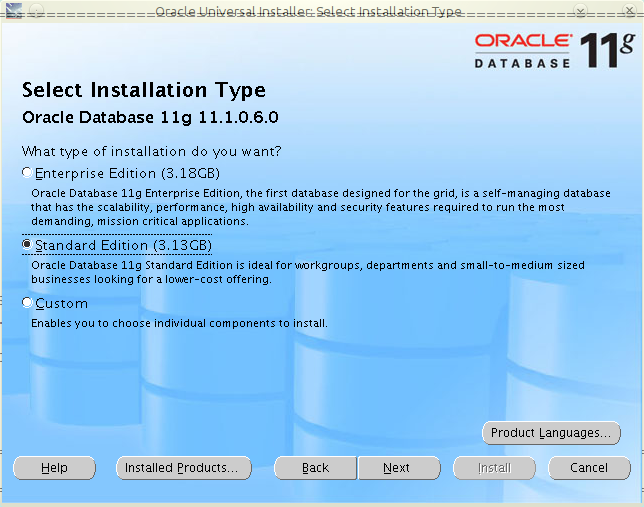
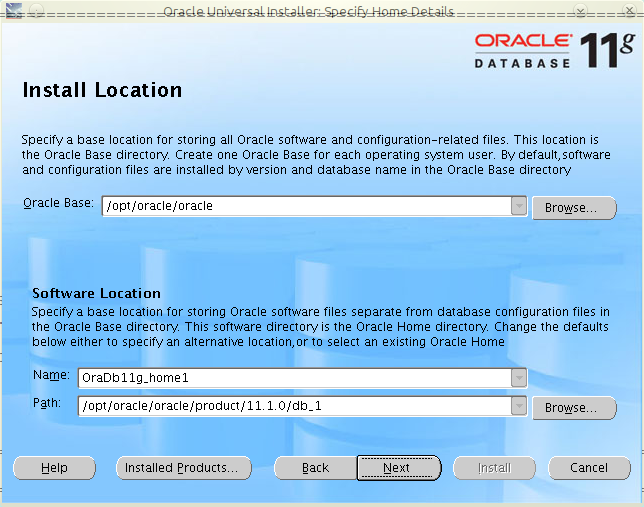
W Javie istnieje możliwość zwiększania wydajności działania aplikacji poprzez zmianę sposobu użycia pamięci. Istnieje możliwość użycia Huge Memory Pages. Pozwalają one na użycie przez aplikację stron pamięci o większym rozmiarze niż standardowe 4kB (np. w przypadku Linuksa o rozmiarze 2048kB).
Użycie takich stron pozwala na zmniejszenie ilości mapowań dokonywanych przez TLB (Translation lookaside buffer). Niestety, przynajmniej w przypadku Linuksa przed użyciem takiej pamięci należy odpowiednio skonfigurować system operacyjny, czyli zarezerwować odpowiedni obszar pamięci, który zostanie użyty przez aplikacje. Trzeba pamiętać, że będzie on miał nastepujące właściwości:
- obszar pamięci o dużych rozmiar stron będzie dostępny tylko dla aplikacji, które potrafią i chcą z niego korzystać (czyli jeżeli przeznaczymy za dużo pamięci na ten obszar, może zabraknąć RAMu dla innych aplikacji działających w ramach systemu operacyjnego)
- pamięć ta nigdy nie zostanie zapisanie w pamięci tymczasowej (swap)
- aplikacja musi mieścić się w całości w ramach tego obszaru, więc warto pamiętać że pamięć zajmowana przez JVM to jest suma dwóch wartości, definiowanych przez parametry -Xmx oraz -XX:MaxPermSize
Konfiguracja systemu operacyjnego Linuks
Konfigurację Huge Pages może zostać wykonana na działającym systemie, ale w przypadku za dużej fragmentacji pamięci może się nie powieść. W zawiązku z tym po zapisaniu zmian w pliku
/etc/sysctl.conf przydatny może byc restart serwera.Pierwszym krokiem będzie zdefiniowanie maksymalnego obszaru pamięci, jak ma zostać przeznaczony dla JVM. Najłatwiej zrobić to, umieszczając w pliku /etc/sysctl.conf następujący zapis:
73 | kernel.shmmax = 1073741824 |
Wartość dla parametru należy podać w bajtach, ja zdefiniowałem ją na 1GB (1024 * 1024 * 1024). Parametr ten definiuje maksymalny obszar pamięci jaki za zostać przeznaczony dla aplikacji, ale wymagana jest jeszcze zdefiniowanie faktycznej ilości stron pamięci, jaka zostanie użyta. Robi się to przy użyciu parametru:
74 | vm.nr_hugepages = 512 |
Rozmiar pojedynczej strony pamięci można sprawdzić przy użyciu plecenia:
Kolejnym krokiem będzie utworzenie specjalnej grupy w systemie operacyjnych, której członkowie będą mieli możliwość korzystania z tej specjalnej pamięci:
Teraz trzeba jeszcze poznań numer GID tej grupy:
W moim przypadku będzie to numer 1005.
Teraz jeszcze należy poinformować system, że członkowie tej grupy będą mieli możliwość zapisywania do pamięci:
75 | vm.hugetlb_shm_group = 1005 |
Dodajmy użytkownika jboss do zdefiniowanej grupy:
Ostatnim krokiem będzie możliwości blokowania stron przez danego użytkownika. Robi się to w pliku /etc/security/limits.conf poprzez umieszczenie takiego wpisu:
61 62 | jboss soft memlock unlimited jboss hard memlock unlimited |
Tym sposobem system operacyjny jest już skonfigurowany poprawnie, więc pozostaje uruchomić maszynę wirtualną tak, aby wykorzystała dostępną pamięć z dużymi rozmiarami strony. Robi się to przekazując parametr -XX:+UseLargePages w momencie uruchamiania JVM.
W przypadku serwera aplikacji JBoss najlepiej jest dodać parametr -XX:+UseLargePages w pliku konfiguracyjnym run.conf w miejscu definiowania zmiennej środowiskowej JAVA_OPTS. Po tym kroku można już uruchomić serwer.
Ilość zużytych bloków pamięci można sprawdzić przy użyciu komendy: